Локальный K8s для тестов


Для локальных экспериментов я выбрал minikube. Различных инструментов для запуска локального кластера много. Я посмотрел статьи сравнения вроде вот этой, миникуб оказался самым удачным. Некоторые варианты запускают ноды кластера на виртуальных машинах. Возможно это дает каки-то дополнительные возможности. Для моих целей ноды, которые крутятся как контейнеры в докере на одной машине было достаточно.
Кластер
Предположим, что миникуб у вас установлен. Так же нужно установить helm — пакетный менеджер для k8s.
minikube start --nodes 2 --insecure-registry "10.0.0.0/24" --disk-size 35000mb- Я запустил кластер из 2 узлов. Планировал через chaos mesh ронять один из них, но в видео это не попало. Для экспериментов хватит кластера и на одном узле.
- Обращу внимание, что я увеличил объем доступной дисковой памяти для кластера. Первый кластер ночью завис уперевшись в диск.
- Так же нужно указать, что реестр образов у нас не https.
Аддоны
minikube addons enable registry
minikube addons enable ingress- Аддон с реестром образов
- Аддон с HTTP точкой входа в кластер, можно и без него пробросить порты, но с ним получается по-настоящему.
Дашборд
Чтобы удобнее за всем наблюдать запустим туннель в кластер и k8s дашборд. При запуске каждого нового ingress нужно набирать пароль для туннеля. Поэтому если вы накатили новый ingress, а доступа нет — загляните во вкладку с minikube tunnel он снова будет просить пароль.
minikube tunnel
minikube dashboard --url --port=5001
Мониторинг и Хаос
Спульте репку. Все команды запускаем из директории с кодом. Потому что при установке используются yaml с настройками. Еще важное замечание: все сервисы настроены без постоянного хранилища. При перезапуске кластера все дашборды в Grafana сбросятся.
Chaos Mesh — это инструмент, который позволяет внедрить в кластер разные неисправности. От падения отдельного пода, до потери части сети. Дефекты можно запускать разово, а можно по расписанию. Можно даже составлять сложные сценарии падений. Где сперва падает одно, цепляет другое и вот весь кластер летит к чертям. Веселье! Рекомендую.
kubectl create ns chaos
helm repo add chaos-mesh https://charts.chaos-mesh.org
helm install chaos-mesh chaos-mesh/chaos-mesh -n=chaos --version 2.5.1 --set dashboard.create=true
- Создаем
namespacechaos, чтобы изолировать сам Chaos Mesh. - Добавим репозиторий в helm
- Установим все включая дашборд. Chaos Mesh можно управлять и через yaml файлы, но с интерфейсом приятнее.
В k8s все устанавливается не моментально. Поэтому после того, как helm отработает нужно подождать пока все поды стартуют. За процессом можно наблюдать на дашборде k8s, который мы открыли на предыдущем шаге.
Дашборд Chaos Mesh поднимается на порту 2333. Перенаправим порт, чтобы получить доступ к панели управления. Можно было бы сконфигурировать сервис и подключить дашборд к ингресу, но я решил не тратить на это время.
kubectl port-forward -n chaos svc/chaos-dashboard 2333:2333
При логине панель попросит у нас ключ и подскажет, как его сгенерировать. Создайте токен с доступом ко всему кластеру на права менеджера:
kubectl apply -f chaos-mesh-admin.yaml
kubectl create token account-cluster-manager-ugbmq
Мониторинг
Без мониторинга вообще ни одна система не должна уходить в продакшен. Поэтому тестовые системы тоже нужно приучаться мониторить. Мы ведь хотим научиться видеть ошибки на мониторинге. Поэтому установим простой стек из Loki для сбора логов со всех систем, Prometheus для сбора метрик и Grafana чтобы все это можно было посмотреть.
Для установки Loki и Grafana я использовал этот урок: Setup Grafana/Loki on Local K8s Cluster — Minikube.
kubectl create namespace monitoring
helm repo add loki https://grafana.github.io/loki/charts
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm upgrade --install loki --namespace=monitoring grafana/loki-stack
helm upgrade --install grafana --namespace monitoring -f grafana-install.yaml grafana/grafana
Локи должен заработать из коробки. Генерируем пароль к Графане:
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
Далее установим Prometheus:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install prometheus prometheus-community/prometheus --namespace monitoring --set server.persistentVolume.enabled=false
kubectl port-forward -n monitoring svc/prometheus-server 9090:80- Здесь важно отметить
--set server.persistentVolume.enabled=falseя запустил Prometheus без постоянного хранилища.
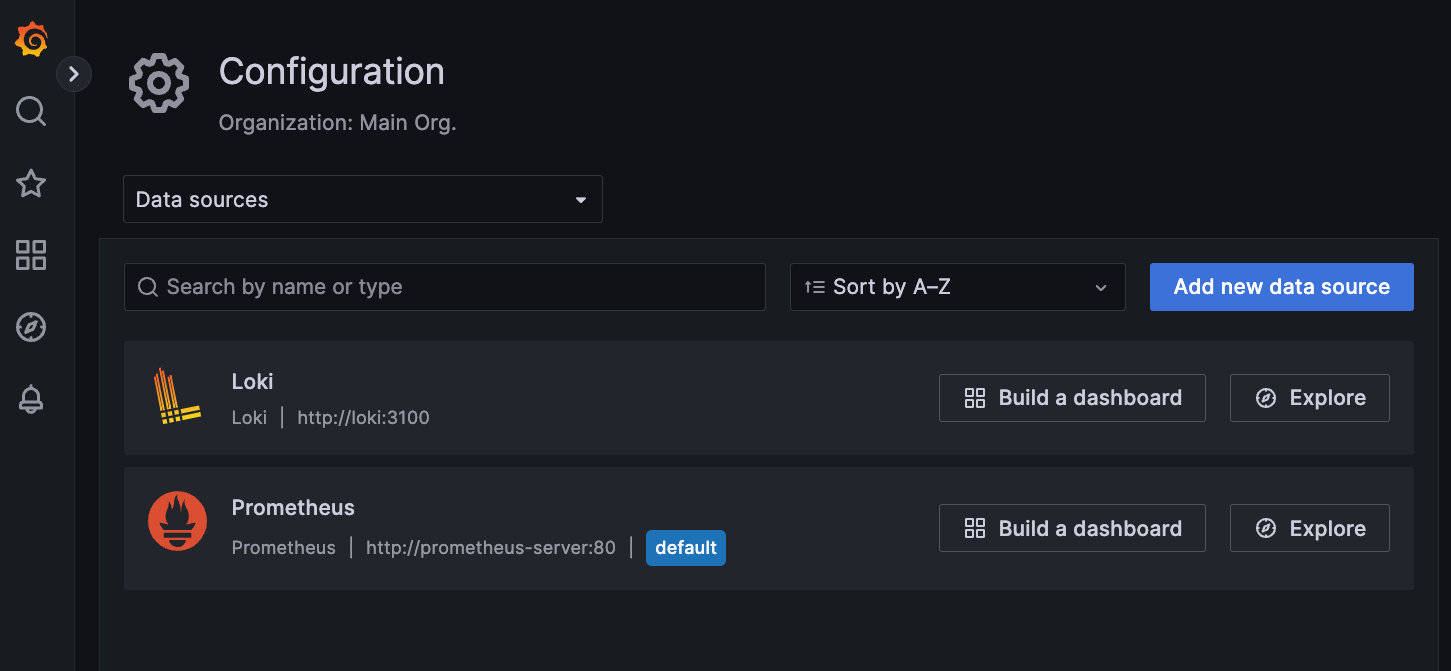
Далее в Grafana добавим источники данных для Loki и Prometheus. Там надо указать только адрес сервисов. Для Loki: http://loki:3100, для Prometheus: http://prometheus-server:80
И загрузим дашборд из файла grafana-dashboard.json
Приложение
В коде приложения используем специальный адрес host.minikube.internal. Он уже прописан в DNS кластера, поэтому запрос с фронтенда идущего на этот адрес придет на ingress и будет перенаправлен на API.
Чтобы этот адрес заработал, нужно добавить его в хосты sudo vim /etc/hosts. На винде это как-то похоже делается, вы сами поглулите. У меня в хостах еще grafana.
127.0.0.1 grafana.minikube
127.0.0.1 host.minikube.internalТеперь можно собрать докеры с приложением и загрузить все на кластер.
docker build -t ssv/reliability-frontend:idemp-fixed ./frontend
minikube image load ssv/reliability-frontend:idemp-fixed
kubectl apply -f frontend.yamldocker build -t ssv/reliability-services:idemp-fixed ./services
minikube image load ssv/reliability-services:idemp-fixed
kubectl apply -f nats.yaml
kubectl apply -f services.yamlПеред стартом сервисов вы заметили, что мы запустили NATS. Это сервер обмена сообщений. С его помощью сервисы фреймворка Moleculer будут между собой общаться.
Тестирование
После того как все сервисы поднялись можно начинать тестировать.
Ввиду некоторых ограничений Chaos Mesh я внедрил некоторые баги прямо в приложение. Управляются они через переменную в localStorage на фронтенде.
localStorage.setItem(
"chaosErrors",
"dbTicketsDelay=3000&dbErrorRate=0.5&ticketsErrorRate=0"
);Всего доступно 3 параметра:
dbTicketsDelay=3000задержка обратного ответа от "базы данных" с билетами в милисекундахdbErrorRate=0.5частота ошибок, которые выдает "база данных" с конференциями.ticketsErrorRate=0частота ошибок, которые выдает сервис количества проданных билетов.
На самом деле я рассчитываю, что вы попробуете похаосить свое собственное приложение. Надеюсь, что у вас все получится! Если возникнут вопросы — пишите!
Материалы
- Весь код: https://github.com/seniorsoftwarevlogger/reliability
- Фреймворк: https://moleculer.services/
- Книга: Release it! - Michael T. Nygard
- Отличная документация на паттерны от MSFT
- Книжка про микросервисы
- Как правильно рейт лимитить
- Еще документации от AWS про backoff and jitter
- Установка Локи и Графаны на миникуб